数据库-单表
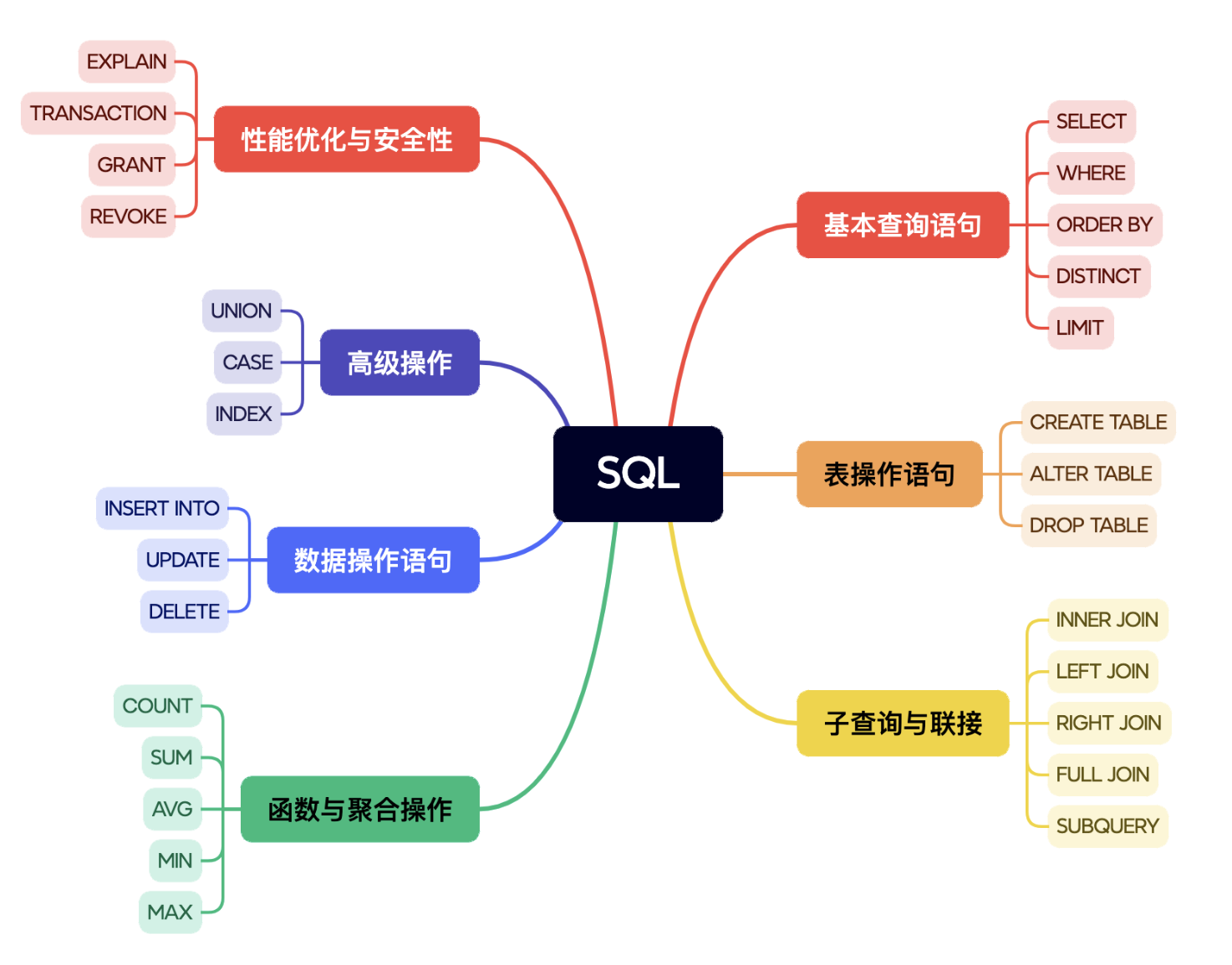
DDL语句用于操作数据库以及表结构
数据库操作-DDL
创建数据库
create database [ if not exists ] 数据库名;删除数据库
drop database [ if exists ] 数据库名 ;表操作
创建
create table 表名(
字段1 字段1类型 [约束] [comment 字段1注释 ],
字段2 字段2类型 [约束] [comment 字段2注释 ],
......
字段n 字段n类型 [约束] [comment 字段n注释 ]
) [ comment 表注释 ] ;示例
create table tb_user (
id int comment 'ID,唯一标识', # id是一行数据的唯一标识(不能重复)
username varchar(20) comment '用户名',
name varchar(10) comment '姓名',
age int comment '年龄',
gender char(1) comment '性别'
) comment '用户表';
约束
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
修改表
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];示例
alter table tb_emp add qq varchar(11) comment 'QQ号码';
修改数据类型
仅修改字段的数据类型、长度或约束,不改变字段名
alter table 表名 modify 字段名 新数据类型(长度);同时重命名字段并修改其数据类型、长度、注释或约束
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];删除字段
alter table 表名 drop 字段名;修改表名
rename table 表名 to 新表名;删除表
drop table [ if exists ] 表名;数据库操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
增加(insert)
向指定字段添加数据
insert into 表名 (字段名1, 字段名2) values (值1, 值2);全部字段添加数据
insert into 表名 values (值1, 值2, ...);修改(update)
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;删除(delete)
delete from 表名 [where 条件] ;案例1:删除tb_emp表中id为1的员工
delete from tb_emp where id = 1;
案例2:删除tb_emp表中所有员工
delete from tb_emp;
注意事项:
• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
• DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
• 当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
数据库操作-DQL
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询分为
DQL语句-单表操作
DQL语句-多表操作
语法
DQL查询语句,语法结构如下:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
基本查询(不带任何条件)
条件查询(where)
分组查询(group by)
排序查询(order by)
分页查询(limit)
基本查询
查询多个字段
select 字段1, 字段2, 字段3 from 表名;查询所有字段(通配符)
select * from 表名;设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;去除重复记录
select distinct 字段列表 from 表名;
条件查询
select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件在SQL语句当中构造条件的运算符分为两类:
比较运算符
逻辑运算符
常用的比较运算符如下:
常用的逻辑运算符如下:
聚合函数
之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:
select 聚合函数(字段列表) from 表名 ;注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];where与having区别(面试题,当时没明白面试官意思)
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;排序方式:
ASC :升序(默认值)
DESC:降序
分页查询
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;